






















InfiniBand VS. RoCE v2:Which is Best Network Architecture for AI Computing Center?
 Gavin InfiniBand Network Engineer Aug 15, 2023
Gavin InfiniBand Network Engineer Aug 15, 2023 Generally, in AI computing systems, the lifecycle of a model, from development to deployment, typically involves two major stages: offline training and inference deployment. Comprehensive analysis of high-performance networks such as InfiniBand (IB) and RDMA over Converged Ethernet (RoCE) v2 is common, as evaluation results contribute to selecting models suitable for specific application scenarios and optimizing system performance to achieve better efficiency and effectiveness.
Typical issues during the network selection and deployment phase in intelligent computing include:
- Is the intelligent computing network built on top of the existing TCP/IP general network infrastructure or is a dedicated high-performance network created?
- Does the intelligent computing network adopt InfiniBand or RoCE as the technology solution?
- How is the intelligent computing network maintained and managed?
- Does the intelligent computing network possess multi-tenant isolation capability to enable internal and external operations?
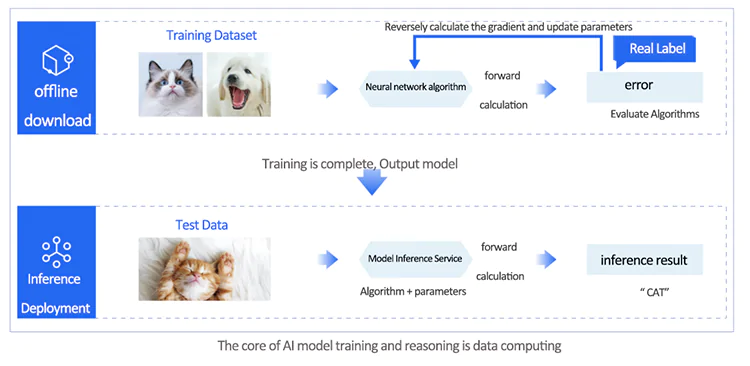
Offline training is the process of generating a model. Users need to prepare the required dataset and neural network algorithm based on their task scenarios. During the model training, data is read, fed into the model for forward computation, and the error with respect to the true values is calculated. Then, the backward computation is performed to obtain parameter gradients, and the parameters are updated. The training process involves multiple rounds of data iteration. After training is completed, the trained model is saved and deployed for online inference, where it receives real user inputs, performs forward computation, and completes inference. Therefore, whether it is training or inference, the core is data computation. To accelerate computational efficiency, training and inference are generally performed using heterogeneous acceleration chips such as GPUs.
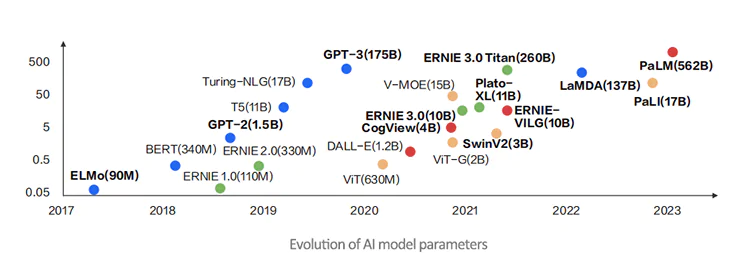
With large models like GPT-3.0 demonstrating impressive capabilities, the trend in intelligent computing is moving towards the development of models with massive numbers of parameters. This is especially evident in the field of Natural Language Processing (NLP), where model parameters have reached the scale of hundreds of billions. Model parameter sizes in other domains such as Computer Vision (CV), advertising recommendation, and intelligent risk control are also expanding, heading towards the scale of tens or hundreds of billions.
In the context of autonomous driving, each vehicle generates data at the terabyte level on a daily basis, and training data for each iteration reaches the petabyte scale. Large-scale data processing and simulation tasks have distinct characteristics, requiring the use of intelligent computing clusters to enhance the efficiency of data processing and model training.
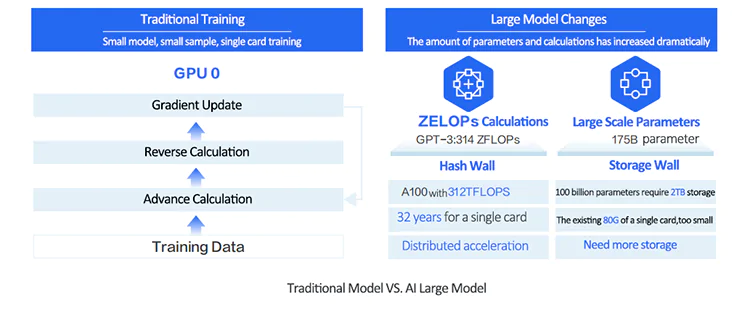
The large-scale parameters in training large models pose higher requirements on computing power and GPU memory. Taking GPT-3 as an example, a model with hundreds of billions of parameters requires 2TB of GPU memory, which exceeds the current capacity of a single GPU. Even with the availability of GPUs with larger memory capacity, training such a model on a single GPU would still take approximately 32 years. To reduce training time, distributed training techniques are commonly employed. These techniques involve partitioning the model and data and utilizing multiple machines and GPUs, allowing the training duration to be shortened to the scale of weeks or days.
Distributed training is a technique that addresses the challenges of computing power and storage limitations in large-scale model training by building a cluster of multiple nodes with high computational and GPU memory capabilities. The high-performance network connecting this supercluster directly determines the communication efficiency between intelligent computing nodes, thereby affecting the throughput and performance of the entire intelligent computing cluster. To achieve high throughput for the entire intelligent computing cluster, a high-performance network needs to have key capabilities such as low latency, high bandwidth, long-term stability, scalability, and manageability.
The overall computing power of a distributed training system does not simply increase linearly with the addition of intelligent computing nodes but rather exhibits an acceleration ratio, which is typically less than 1. The presence of an acceleration ratio is mainly due to the fact that in distributed scenarios, the computation time for a single training step includes both the computation time on individual GPUs and the communication time between GPUs. Therefore, reducing the inter-GPU communication time is crucial for improving the acceleration ratio in distributed training and requires careful consideration and design.
RDMA (Remote Direct Memory Access) technology is a key technique for reducing end-to-end communication latency between multiple machines and GPUs. RDMA allows a host to directly access the memory of another host, bypassing the operating system kernel.
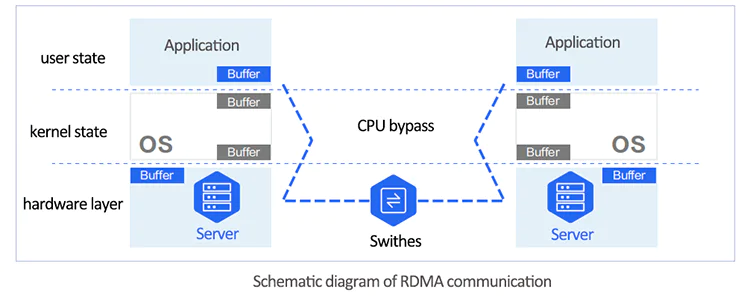
There are four implementations of RDMA technology: InfiniBand, RoCEv1, RoCEv2, and iWARP. Among them, RoCEv1 has been deprecated, and iWARP is less commonly used. Currently, the primary solutions for RDMA technology are InfiniBand and RoCEv2.
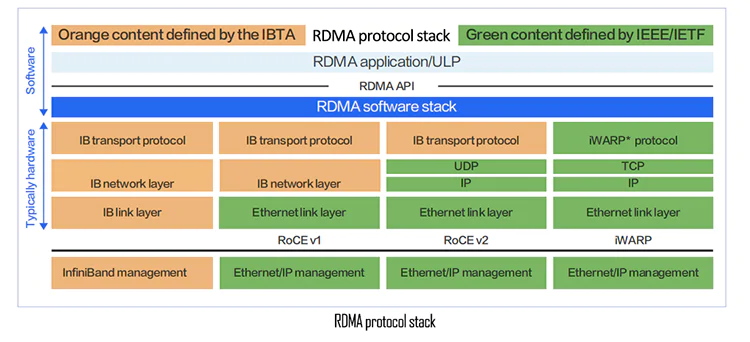
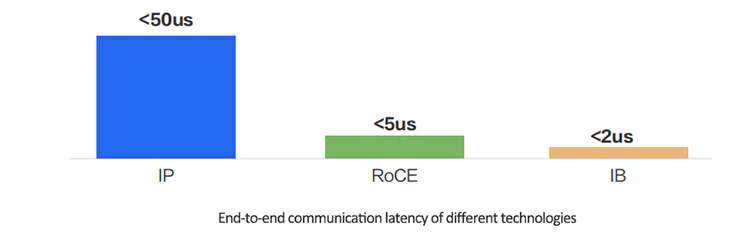
In the InfiniBand and RoCEv2 solutions, the latency performance can be improved by several orders of magnitude compared to traditional TCP/IP networks because they bypass the kernel protocol stack. In scenarios where communication within the same cluster can be achieved in a single hop, experimental testing in laboratory settings has shown that after bypassing the kernel protocol stack, the end-to-end latency at the application layer can be reduced from 50us (TCP/IP) to 5us (RoCE) or 2us (InfiniBand).
After completing a computational task, the computing nodes within the intelligent computing cluster need to quickly synchronize the computation results with other nodes to proceed to the next round of computation. The computation task waits until the result synchronization is complete before entering the next round. If the available bandwidth is insufficient, the gradient transfer slows down, resulting in longer inter-GPU communication time and, consequently, impacting the acceleration ratio.
To meet the requirements of low latency, high bandwidth, stable operation, scalability, and ease of management in intelligent computing networks, the commonly used network solutions in the industry are the InfiniBand solution and the RoCEv2 solution.
1. InfiniBand Network Introduction
The key components of an InfiniBand network include the Subnet Manager (SM), InfiniBand network cards, InfiniBand switches, and InfiniBand cables.
NVIDIA is a major manufacturer that supports InfiniBand network cards. The following diagram shows commonly available InfiniBand network cards. InfiniBand network cards have been rapidly advancing in terms of speed. The 200Gbps HDR has already been deployed on a large scale for commercial use, and network cards with 400Gbps NDR are also starting to be commercially deployed.

In the realm of InfiniBand switches, the SB7800 is a 100Gbps port switch (36*100G) and is one of NVIDIA's earlier generation products. The Quantum-1 series is a 200Gbps port switch (40*200G) and is widely adopted in the current market.
In 2021, NVIDIA introduced the Quantum-2 series switch with 400Gbps capacity (64\*400G). This switch features 32 800G OSFP (Octal Small Form Factor Pluggable) ports, which require cable adapters to provide 64 400G QSFP connections.
InfiniBand switches do not run any routing protocols. The forwarding tables for the entire network are calculated and distributed by a centralized Subnet Manager (SM). In addition to the forwarding tables, the SM is responsible for managing configurations such as Partitions and QoS within the InfiniBand subnet. InfiniBand networks require dedicated cables and optical modules for interconnecting switches and connecting switches to network cards.
As a leading provider of comprehensive optical network solutions, NADDOD offers lossless network solutions based on InfiniBand (400G/800G NDR, 200G HDR) and RoCE, enabling users to build lossless network environments and high-performance computing capabilities. NADDOD can tailor the optimal solution to different application scenarios and user requirements, providing high bandwidth, low latency, and high-performance data transmission to effectively address network bottlenecks, enhance network performance, and improve user experience.
NADDOD's InfiniBand AOC/DAC products can meet connectivity requirements ranging from 0.5m to 100m distances, and they offer lifetime technical support. With superior customer service and products that reduce costs and complexity while delivering exceptional performance to server clusters, NADDOD is your go-to choice. Visit the NADDOD official website for more information!
2. InfiniBand Network Solution Features
(1) Native Lossless Network
InfiniBand networks utilize a credit-based signaling mechanism to fundamentally avoid buffer overflow and packet loss. The sending end will only initiate packet transmission after confirming that the receiving end has sufficient credits to accept the corresponding number of packets. Each link in the InfiniBand network has a predetermined buffer. The sending end will not transmit data beyond the available predetermined buffer size at the receiving end. Once the receiving end completes forwarding, it frees up the buffer and continuously returns the current available predetermined buffer size to the sending end. This link-level flow control mechanism ensures that the sending end never sends an excessive amount of data, preventing buffer overflow and packet loss in the network.
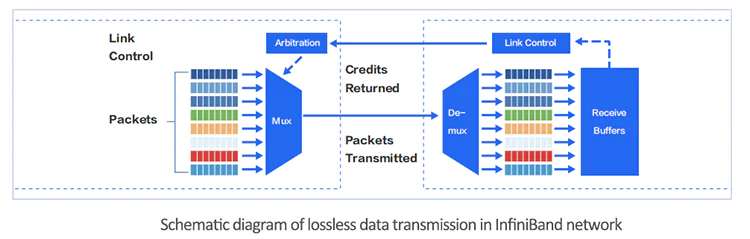
(2) Network Card Expansion Capability
InfiniBand's Adaptive Routing is based on per-packet dynamic routing, ensuring optimal utilization of the network in large-scale deployments. InfiniBand networks have numerous examples of large GPU clusters, such as those found in Baidu AI Cloud and Microsoft Azure.
Currently, there are several major providers of InfiniBand network solutions and accompanying equipment in the market. Among them, NVIDIA holds the highest market share, exceeding 70%.
- NVIDIA: NVIDIA is one of the primary vendors of InfiniBand technology, offering various InfiniBand adapters, switches, and related products.
- Intel Corporation: Intel is another significant supplier of InfiniBand, providing a range of InfiniBand network products and solutions.
- Cisco Systems: Cisco is a well-known network equipment manufacturer that also offers InfiniBand switches and other related products.
- Hewlett Packard Enterprise: HPE is a large IT company that provides various InfiniBand network solutions and products, including adapters, switches, and servers.
These providers offer products and solutions that cater to different user requirements and support InfiniBand network deployments of various scales and application scenarios.
3. RoCE v2 Network Introduction
An InfiniBand network is, to some extent, a centrally managed network with a SM (Subnet Manager). A RoCEv2 network, on the other hand, is a purely distributed network consisting of RoCEv2-capable NICs and switches, typically in a two-tier architecture.
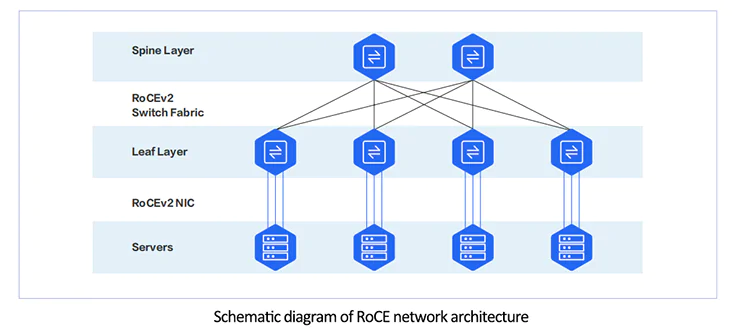
There are several manufacturers that offer RoCE-enabled network cards, with the main vendors being NVIDIA, Intel, and Broadcom. PCIe cards are the primary form of data center server network cards. The port PHY speed of RDMA cards typically starts at 50Gbps, and currently available commercial network cards can achieve single-port speeds of up to 400Gbps.

Most data center switches currently support RDMA flow control technology, which, when combined with RoCE-enabled network cards, enables end-to-end RDMA communication. Leading global data center switch vendors include Cisco, Hewlett Packard Enterprise (HPE), Arista, and others. These companies provide high-performance and reliable data center switch solutions to meet the demands of large-scale data centers. They have extensive experience in networking technology, performance optimization, and scalability, and have gained wide recognition and adoption worldwide.
The core of high-performance switches lies in the forwarding chips they utilize. In the current market, Broadcom's Tomahawk series chips are widely used in commercial forwarding chips. Among them, the Tomahawk3 series chips are more commonly used in current switches, and there is also a gradual increase in switches supporting the Tomahawk4 series chips in the market.
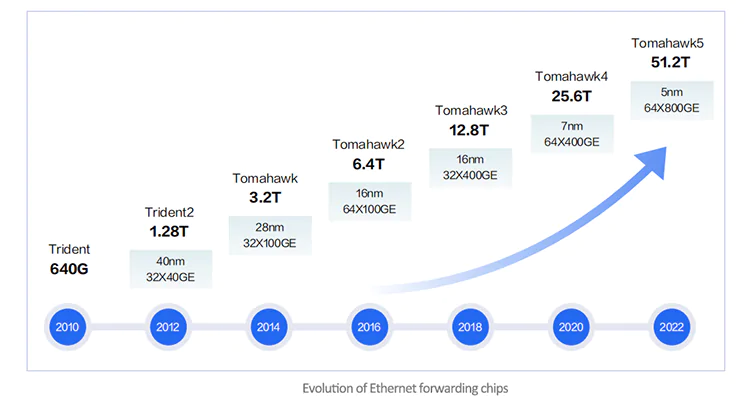
RoCE v2 is carried on Ethernet, so both optical fibers and optical modules of traditional Ethernet can be used.
4. RoCE v2 Network Solution Features
Compared to InfiniBand, RoCE offers the advantages of greater versatility and relatively lower cost. It can be used not only to build high-performance RDMA networks but also in traditional Ethernet networks. However, the configuration of parameters such as Headroom, PFC (Priority-based Flow Control), and ECN (Explicit Congestion Notification) on switches can be complex. In large-scale deployments, such as those with numerous network cards, the overall throughput performance of RoCE networks may be slightly weaker than that of InfiniBand networks.
There are numerous switch vendors that support RoCE, and currently, NVIDIA's ConnectX series of network cards holds a significant market share in terms of RoCE support.
5. InfiBand VS. RoCE v2 Network Solution Comparison
From a technical perspective, InfiniBand employs a variety of technologies to enhance network forwarding performance, reduce fault recovery time, improve scalability, and decrease operational complexity.

In practical business scenarios, RoCEv2 is a good solution, while InfiniBand is an excellent solution.
In terms of business performance: Due to the lower end-to-end latency of InfiniBand compared to RoCEv2, networks built on InfiniBand have an advantage in application-level business performance. However, the performance of RoCEv2 is also capable of meeting the business performance requirements of the majority of intelligent computing scenarios.
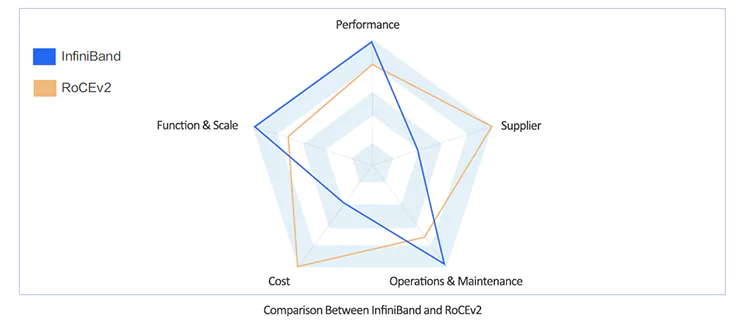
In terms of business scale: InfiniBand can support GPU clusters with tens of thousands of cards while ensuring overall performance without degradation. It also has a significant number of commercial use cases in the industry. RoCEv2 networks can support clusters with thousands of cards without significant degradation in overall network performance.
In terms of business operations and maintenance: InfiniBand is more mature than RoCEv2, offering features such as multi-tenancy isolation and operational diagnostic capabilities.
In terms of business costs: InfiniBand is more expensive than RoCEv2, primarily due to the higher cost of InfiniBand switches compared to Ethernet switches.
In terms of business suppliers: NVIDIA is the main supplier for InfiniBand, while there are multiple suppliers for RoCEv2.
6. Summary - Infiniband preferred for AI network Architecture
In summary, intelligent computing centers are very cautious in selecting network technologies, and InfiniBand, as their preferred solution, brings significant advantages to the computing environment.
InfiniBand demonstrates excellent performance and reliability in high-performance computing environments. By adopting InfiniBand, intelligent computing centers can achieve high-bandwidth, low-latency data transmission, enabling more efficient computation and data processing capabilities, providing users with outstanding services and experiences. In the future, intelligent computing centers will continue to explore and adopt advanced network technologies, continuously enhancing computing capabilities, and driving the progress of scientific research and innovation.