






















Future of RDMA in HPC Cluster
 Quinn InfiniBand Network Architect Jul 11, 2023
Quinn InfiniBand Network Architect Jul 11, 2023 In this era full of challenges and opportunities, understanding and applying RDMA technology has become crucial for building high-performance computing clusters. This article will delve into the principles and application scenarios of RDMA technology, as well as its role in high-performance computing clusters, in order to better understand and apply this important technology.
1. Network Architecture Optimization - Combining Flow Control and Routing
In terms of network architecture, SDN can usually achieve more flexible routing control, while RDMA mainly handles network congestion flow control, and the two have generally existed independently before. RDMA has pushed end-to-end network communication to the extreme. If combined with an overall network view, the combination of the two will undoubtedly achieve better network optimization.
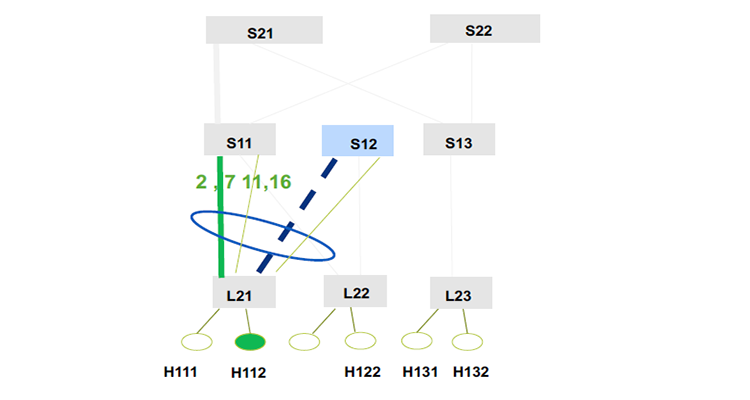
Consider the network communication scenario of a Leaf-Spine architecture. When a congested port occurs on a Spine switch, one approach is to use congestion control to reduce the sending rate of the Leaf switch services. Another approach is to use traffic scheduling, and through an SDN controller, switch some of the Leaf traffic to another available Spine switch. This can optimize the throughput of the entire network.
2. Optimization of Communication Structure for Cluster Applications
Taking a higher-level perspective, in addition to optimizing high-performance networking on the network side, it is also necessary to optimize the communication structure of cluster applications from the source end.
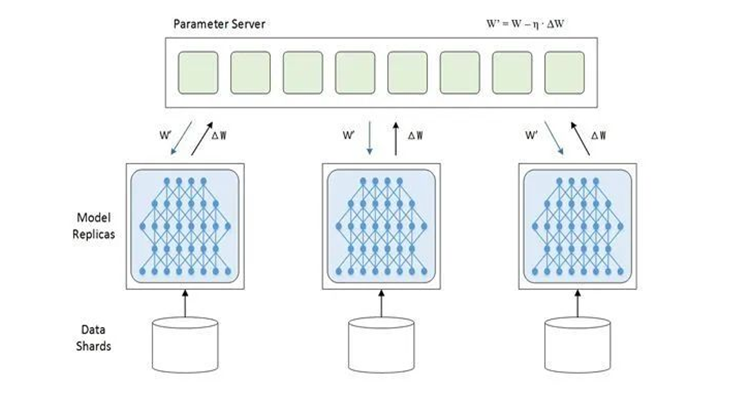
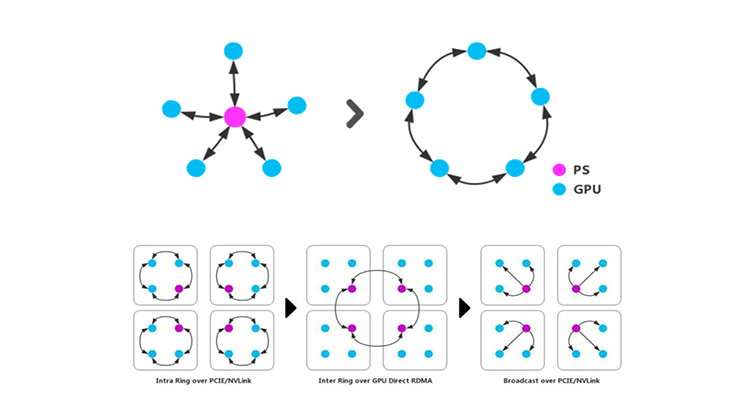
For example, in current distributed learning computations, the commonly used PS-Worker aggregation communication pattern inevitably results in a "many-to-one" scenario, which will put pressure on the PS node. Even if the network layer can handle congestion well, the overall throughput will still be limited. To address this issue, another distributed training method called Horovod changes the communication structure to a ring topology, which can avoid the occurrence of a congestion bottleneck caused by a single node. However, this method may also result in performance loss due to single-point failure or increased hops and delay. Therefore, a distributed AllReduce method has been developed that combines the advantages of both the aggregation and ring topology approaches to comprehensively optimize the model.
3. Choosing the Right Location for Computation
Of course, for high-performance cluster computing, a higher-level perspective involves comprehensive optimization that takes into account both the characteristics of the application and the conditions of the system architecture. As Moore’s Law gradually reaches its limit, heterogeneous chips and domain-specific chips will once again enter a period of explosive growth. Currently, there are various types of heterogeneous chips, including network chips, GPU chips, CPU chips, and FPGA chips. Each has its own processing area of expertise and applicable scenarios. For example, high-throughput forwarding and simple packet processing can be handled by network chips, while vector parallel computing can be handled by GPUs, and complex logic and deep packet inspection can be handled by CPUs. Additionally, scenarios that require both performance and flexibility can be implemented using FPGAs. Therefore, for a dedicated application to fully leverage the advantages of these hardware components, it is necessary to break the mindset of separating network, computing, and storage, and carry out cross-system design to achieve overall optimization. In summary, there is a trend towards a great fusion of networks and computing, and for a complete system, computation should occur in the most suitable location, fully utilizing the value brought by heterogeneous chips.
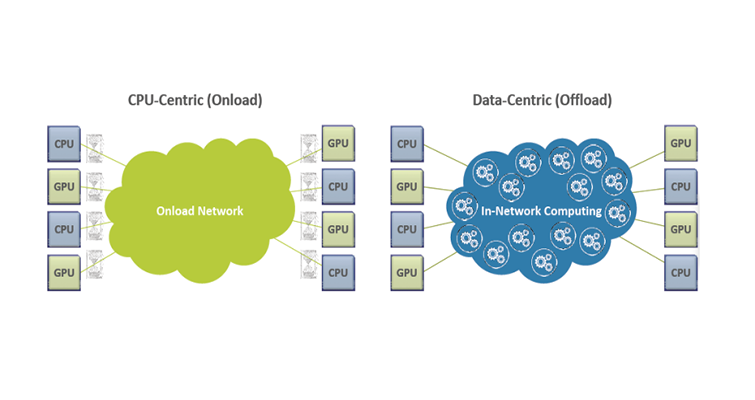
In the context of distributed machine learning, there is also a concept of In-Network Computing, which involves using the high-throughput and high-aggregation capabilities of network chips to perform reduction calculations on the results of distributed computations performed by each node. There are already some implementations available, such as netCache and SwitchML, and Mellanox has been able to perform some calculations on switches using the SHARP architecture in the context of MPI computing. With the emergence of heterogeneous programmable chips in various fields and cloud-native orchestration platforms, flexible scheduling and layout of heterogeneous resources as a whole is gradually becoming possible. The ultimate result is that large-scale data flow-oriented computing can be completed in the shortest possible time, achieving a better balance between data processing and computation.
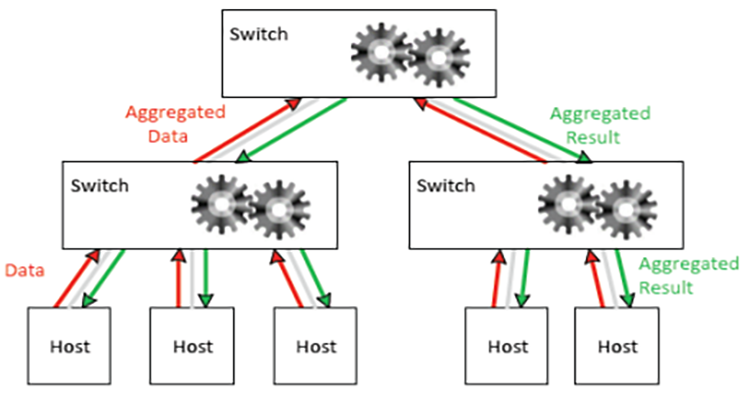
4. Application Scenarios Of RDMA
1. High-performance MPI computing
High-performance MPI computing is one of the earliest application scenarios for Infiniband/RDMA, which is typically used in the supercomputing centers of large scientific research institutions. MPI programs are usually developed using the MPI framework, which makes use of the RDMA API for network communication. MPI computing is widely used in scientific computing fields such as astronomy, meteorology, and fluid mechanics, but it has low popularity in the enterprise market.
2. Big Data/Artificial Intelligence Applications
Applications in the field of big data and AI typically involve the transfer and interaction of massive amounts of data, and exhibit characteristics of both computation-intensive, network-intensive, and I/O-intensive operations. Therefore, they are very suitable for cluster optimization using RDMA technology. Common projects in the big data and AI fields, such as Hadoop, Spark, TensorFlow, and PyTorch, have all added support for RDMA communication interfaces.
3. Distributed Storage/Database
Distributed storage or distributed databases are also high-throughput, data-intensive applications. With the introduction of SSD and NVMe technology, the speed of I/O has also increased significantly. Among them, the Samba file sharing system and Ceph distributed storage have added support for RDMA communication interfaces. In the field of distributed databases, some databases adopt a design that separates computing and storage, and RDMA is also used to accelerate storage operations.
5. In Conclude
RDMA pushes end-to-end network communication to the extreme, with the goal of achieving fast remote data transfer. Technically, it is a combination of multiple optimizations, including kernel bypass on the host side, transport layer NIC offload, and congestion flow control on the network side. The result is low latency, high throughput, and low CPU overhead. However, the current implementation of RDMA also has limitations such as limited scalability, and difficulty in configuration and modification.
When building a high-performance RDMA network, in addition to RDMA adapters and powerful servers, essential components include high-speed fiber optic modules, switches, and fiber optic cables. We recommend choosing Naddod brand for reliable high-speed data transmission products and solutions. As a leading provider of high-speed data transmission solutions, NADDOD offers a variety of high-quality products such as high-performance switches, AOC/DAC/optical modules, and intelligent network cards to meet the low-latency, high-rate data transmission needs. NADDOD’s products and solutions are widely used in various industries, whether it is processing large-scale scientific computing, real-time data analysis, or meeting the low-latency requirements of financial transactions, they have received good reviews. NADDOD’s products will be the ideal choice for you to achieve both economy and efficiency when building a high-performance network!