






















Challenges of deploying Ethernet on AI applications
 Brandon InfiniBand Technical Support Engineer Sep 18, 2023
Brandon InfiniBand Technical Support Engineer Sep 18, 2023 Background Overview
As we all know, the communication method of artificial intelligence (AI) applications can impose a significant burden on networks, posing new challenges for CPU and GPU servers, as well as the underlying network infrastructure that connects these systems. In the era of AI, where data loss during AI training processes is unacceptable, the standard Ethernet network, which inherently experiences packet loss, is no longer suitable. Solving packet loss issues using software-based approaches would greatly impact training results. Therefore, traditional Ethernet networks are no longer adequate for the requirements of AI data centers.
In the field of AI large-scale model training, a single node is insufficient to meet the training demands, and it is often necessary to perform cluster training across multiple GPU nodes. To achieve efficient GPU communication across nodes, GPUDirect RDMA is currently the best solution.
GPUDirect RDMA combines GPU acceleration and Remote Direct Memory Access (RDMA) technology, enabling direct data transfer and communication between GPUs and RDMA network devices. It allows GPUs to access data in RDMA network devices directly, without going through host memory or CPU intermediaries. This reduces CPU load and unleashes the computing power of the CPU.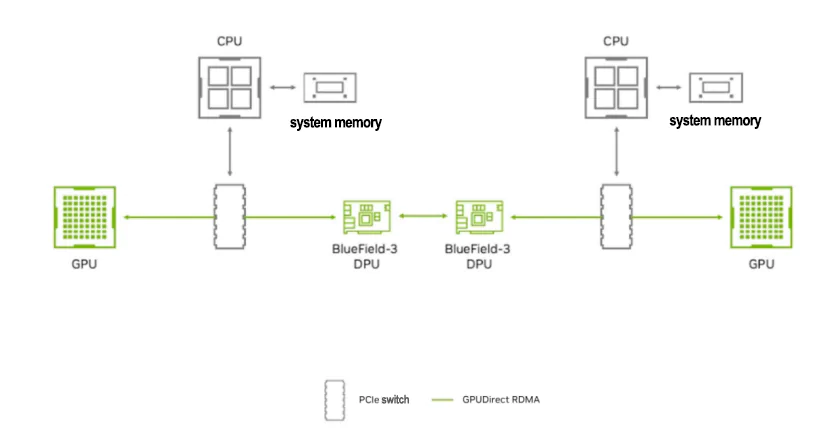
RDMA enables BlueField DPU to directly access GPU memory
Remote Direct Memory Access (RDMA) enables peripheral PCIe devices, such as NVIDIA BlueField DPU, to directly access GPU memory. So, what challenges will be faced when deploying Ethernet for AI applications, and how to solve these challenges?
1. RoCE dynamic routing is required to avoid congestion
A key attribute of scalable IP networks is their ability to carry high-throughput data and flows across multiple switches in an interconnected manner.
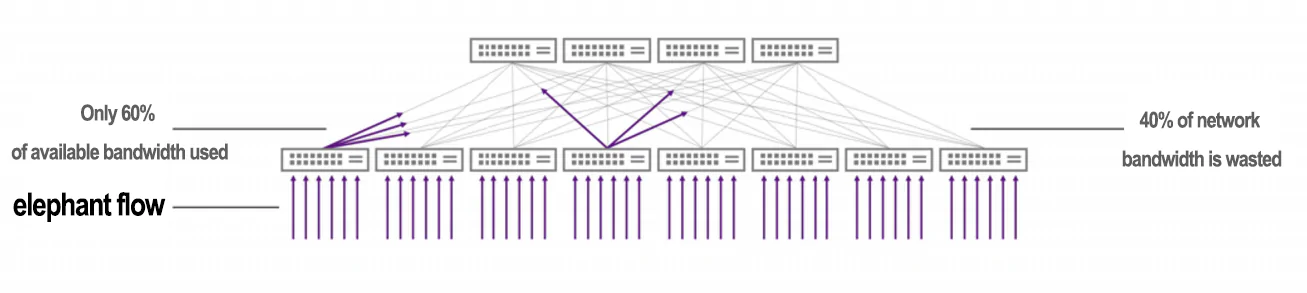
With static load balancing, AI workloads only use 60% of maximum throughput
Ideally, the data flows are completely unrelated, allowing for effective distributed and smooth load balancing across multiple network links. This approach relies on modern hashing and multipath algorithms, including Equal-Cost Multipath (ECMP). Modern data centers are built upon high-port-count, fixed-form-factor switch boxes and extensively leverage ECMP to construct massively scalable networks.
However, in many cases, flow-based hashing with ECMP is not efficient, particularly in ubiquitous modern workloads such as AI and storage.
The issue lies in limited entropy and correlated hash collisions, where an excessive number of elephant flows are sent over the same path. Entropy refers to the measure of randomness in network packets or flows, providing an indication of the amount of information or variability presented in the protocol packet headers.
2. Entropy Problem
Conventional cloud services generate thousands of flows that randomly connect to clients worldwide, resulting in high entropy in the cloud service network. However, AI and storage workloads often generate very large flows. These large AI flows dominate the bandwidth utilization of each link, significantly reducing the total number of flows and leading to very low network entropy. This low-entropy traffic pattern, also known as "elephant flow distribution," is a typical characteristic of AI and high-performance storage workloads.
For traditional IP routing, switches use flow-based (typically 3-tuple or 5-tuple) static hashing to achieve load balancing across all available equal-cost paths and avoid out-of-order packets. This requires high entropy to evenly distribute the traffic across multiple links and prevent congestion. However, in scenarios with elephant flows, where the entropy is low and the flow sizes are large (common in AI networks), multiple flows can be hashed to the same link, resulting in link over-utilization. This over-utilization leads to congestion, increased latency, packet loss, re-transmissions, and ultimately poor application performance.
For many applications, performance depends not only on the average bandwidth of the network but also on the distribution of flow completion times. Long tails or outliers in the completion time distribution significantly degrade application performance. The following are common network typologies in AI networks that are likely to suffer from performance degradation due to long-tail delays.
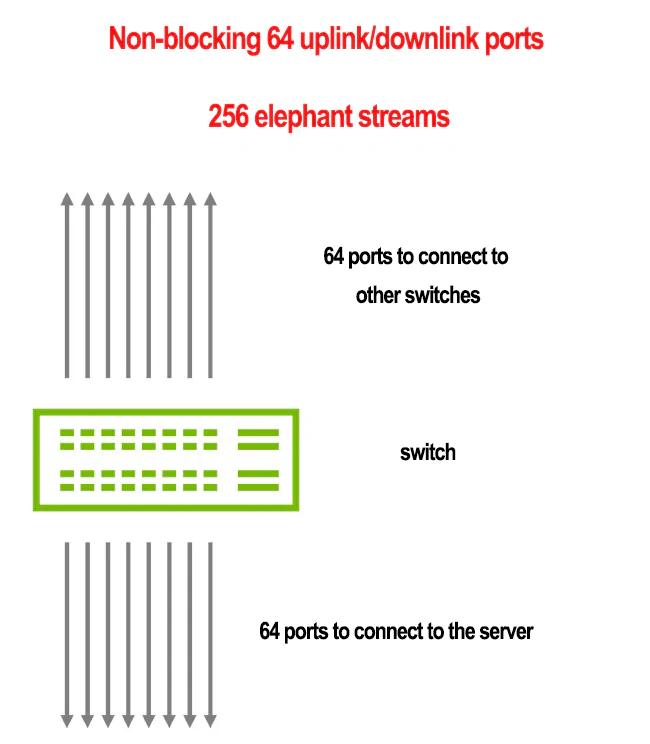
Why Non-Blocking Networks Also Have Long Tail Latencies
This example consists of a single leaf switch with 128 ports, each operating at 400G.
- 64 ports are downlink ports connected to servers.
- 64 ports are uplink ports connected to spine switches.
- Each downlink port receives traffic from 4 flows with the same bandwidth: 100G per flow, totaling 256 flows.
- All traffic from the uplink ports is distributed across ECMP using flow-based hashing.
As the bandwidth levels increase, the likelihood of congestion also increases, resulting in longer flow completion times. In the worst-case scenario, compared to the ideal case, flow completion times can be up to 2.5 times longer.

Stream completion times can vary significantly
In this scenario, some ports experience congestion while others are underutilized. The expected duration of the last flow (the worst flow) is 250% longer than the expected duration of the first flow. This means there are long-tail flows with completion times longer than expected. To avoid congestion with high confidence (98%), you would need to reduce the bandwidth of all flows to below 50%.
Due to the lack of bandwidth awareness in static ECMP hashing, many flows experience long completion times, and certain ports on the switch become highly congested while others are underutilized. As some flows complete transmission and release their corresponding ports, lagging flows pass through the same congested ports, leading to further congestion. This is because the forwarding path is statically chosen after the hashing process completes the packet headers.
3. NVIDIA RoCE Dynamic Routing for Load Balancing
With Spectrum-X, RoCE dynamic routing can be utilized on Spectrum-4 switches. Through dynamic routing, traffic destined for ECMP groups selects the least congested port for transmission. Congestion is evaluated based on the egress queue load, ensuring constant balance across ECMP groups regardless of entropy. Applications that generate multiple requests to multiple servers receive all data with minimal time jitter.
For each packet forwarded to an ECMP group, the switch selects the port with the lowest load in its egress queue for forwarding. The switch evaluates the load on queues that match the traffic class of the packet. When different packets of the same flow are transmitted through different paths in the network, they may arrive at the destination out of order. At the RoCE transport layer, the BlueField-3 DPU handles out-of-order packets and delivers the data to the application in the correct order. This enables applications to transparently benefit from RoCE dynamic routing.
On the sender side, the BlueField-3 DPU can dynamically tag traffic to mark which flows require reordering, ensuring packet inter-arrival order enforcement when needed. The switch's dynamic routing classifier categorizes these tagged RoCE packets and applies unique forwarding mechanisms.
4. Requires NVIDIA RoCE congestion control
When multiple applications run simultaneously on an AI Cloud system, they may experience poor performance and inconsistent runtime due to network congestion. This congestion can be triggered by network traffic from the applications themselves or from background network traffic generated by other applications. A common cause of this type of congestion is many-to-one congestion or incast congestion, characterized by multiple data senders and a single data receiver.
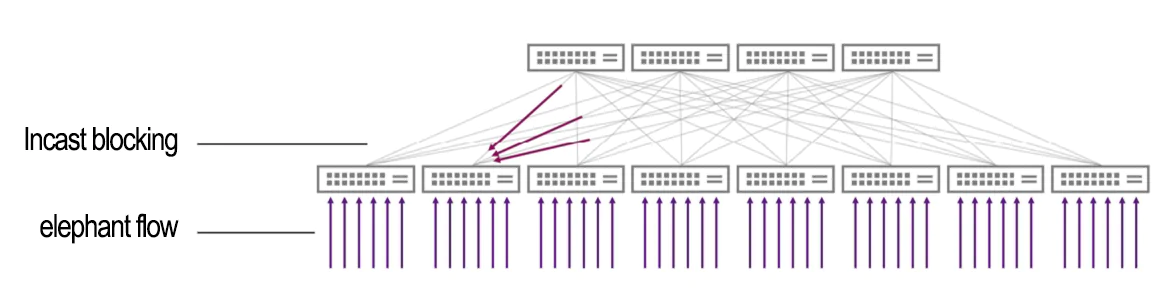
Incast requires NVIDIA RoCE congestion control
Unfortunately, RoCE dynamic routing cannot address this congestion issue as a single receiver cannot distribute the traffic across multiple paths. In such cases, the NVIDIA RoCE congestion control mechanism in Spectrum-X can be employed to mitigate incast congestion.
5. How to deal with changing challenges in the AI era?
Spectrum-X is an Ethernet network platform designed specifically for AI, offering a range of advantages over traditional Ethernet solutions. With higher performance, lower power consumption, reduced total cost of ownership, seamless hardware-software integration, and extensive scalability, Spectrum-X becomes the preferred platform for current and future AI cloud workloads.
In conjunction with NVIDIA-powered Spectrum-X for accelerating AI networks, NADDOD, as a leading provider of optical network connectivity products, offers high-quality DACs, AOCs, and optical modules. Our products have been tested and validated across various industries, backed by deep business understanding and extensive project implementation experience. NADDOD specializes in high-performance network infrastructure and application acceleration, providing optimal solutions tailored to different application scenarios, including high-performance switches, intelligent NICs, and AOC/DAC/optical module product combinations. With our technical expertise and project experience in optical networking and high-performance computing, we consistently deliver exceptional products, solutions, and technical services for data centers, high-performance computing, edge computing, and artificial intelligence applications.
Choosing NADDOD's high-quality and reliable optical connectivity products will bring outstanding performance and reliability to AI deployments on the Spectrum-X network platform, empowering your business to thrive at high speeds!