



















1.6T OSFP224 Hot











1.6T OSFP224 ACC New




Klicken Sie hier, um die erweiterte Ansicht zu öffnen




Artikel im Rampenlicht
NVIDIA/Mellanox® MMS4X00-NS Kompatibles 800G 2xDR4/DR8 InfiniBand NDR Optisches Transceiver-Modul (Twin-Port OSFP, 1310nm, 100m, Zwei MPO-12/APC, DOM, für SMF, gekühlte Oberseite)
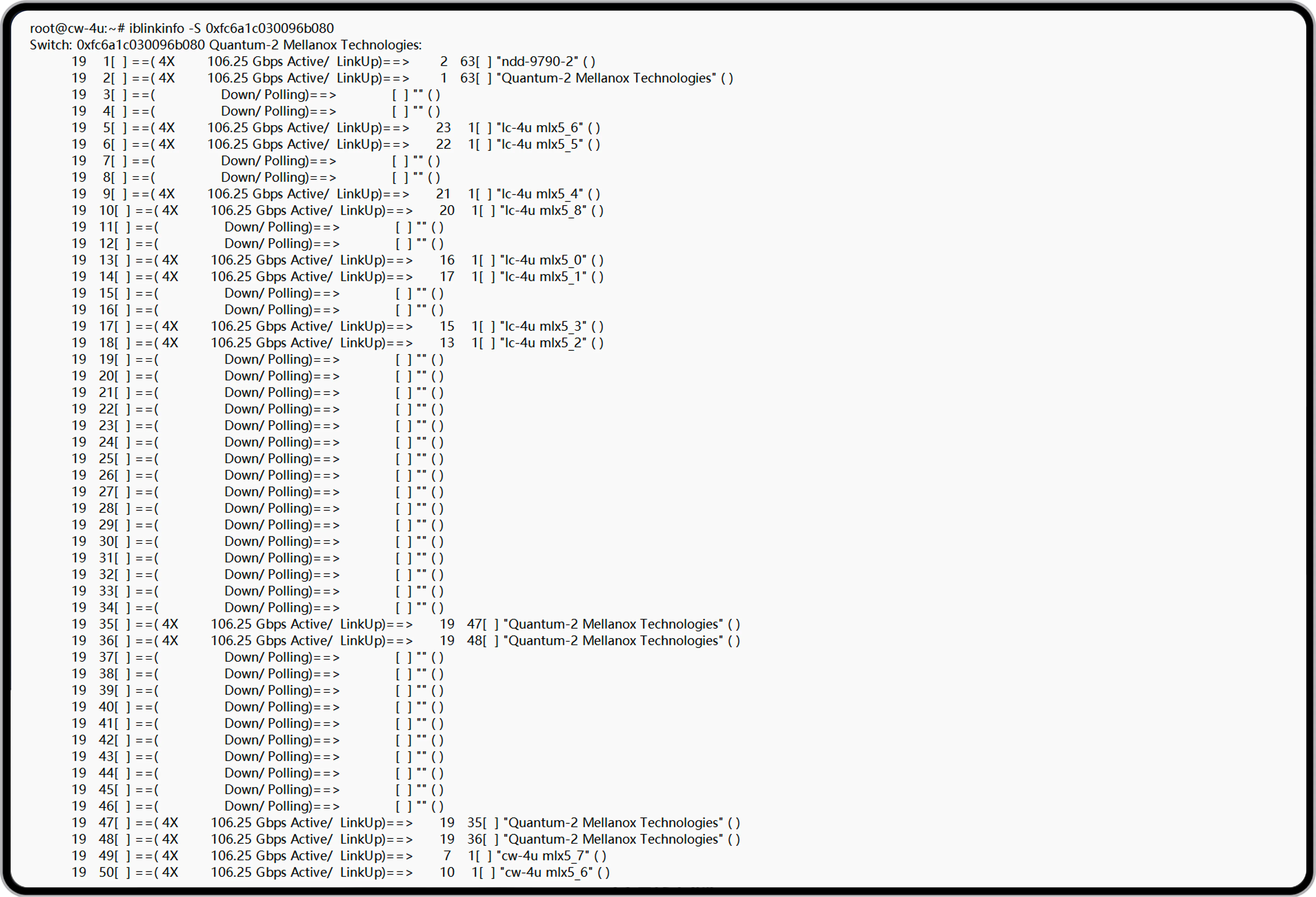
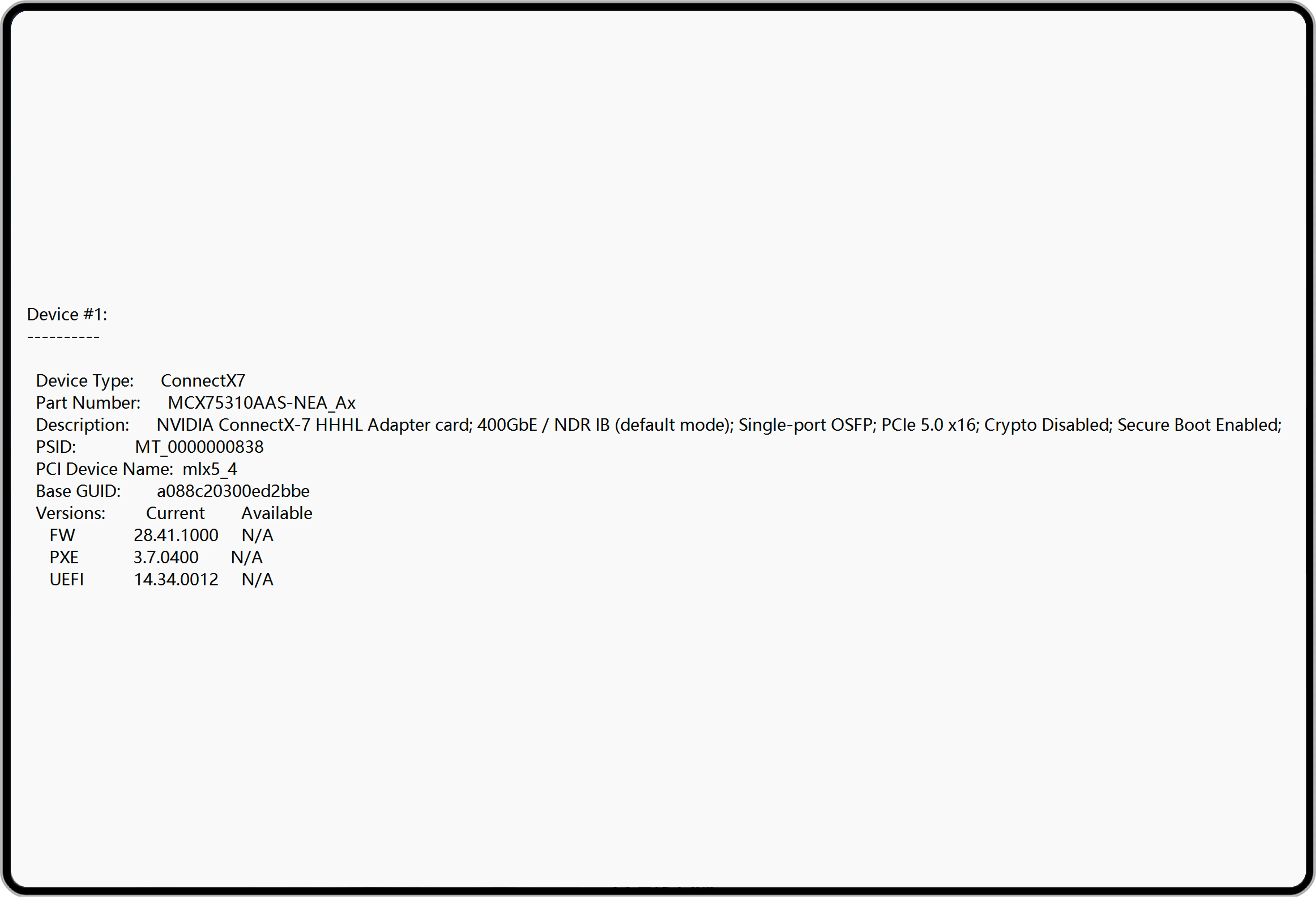
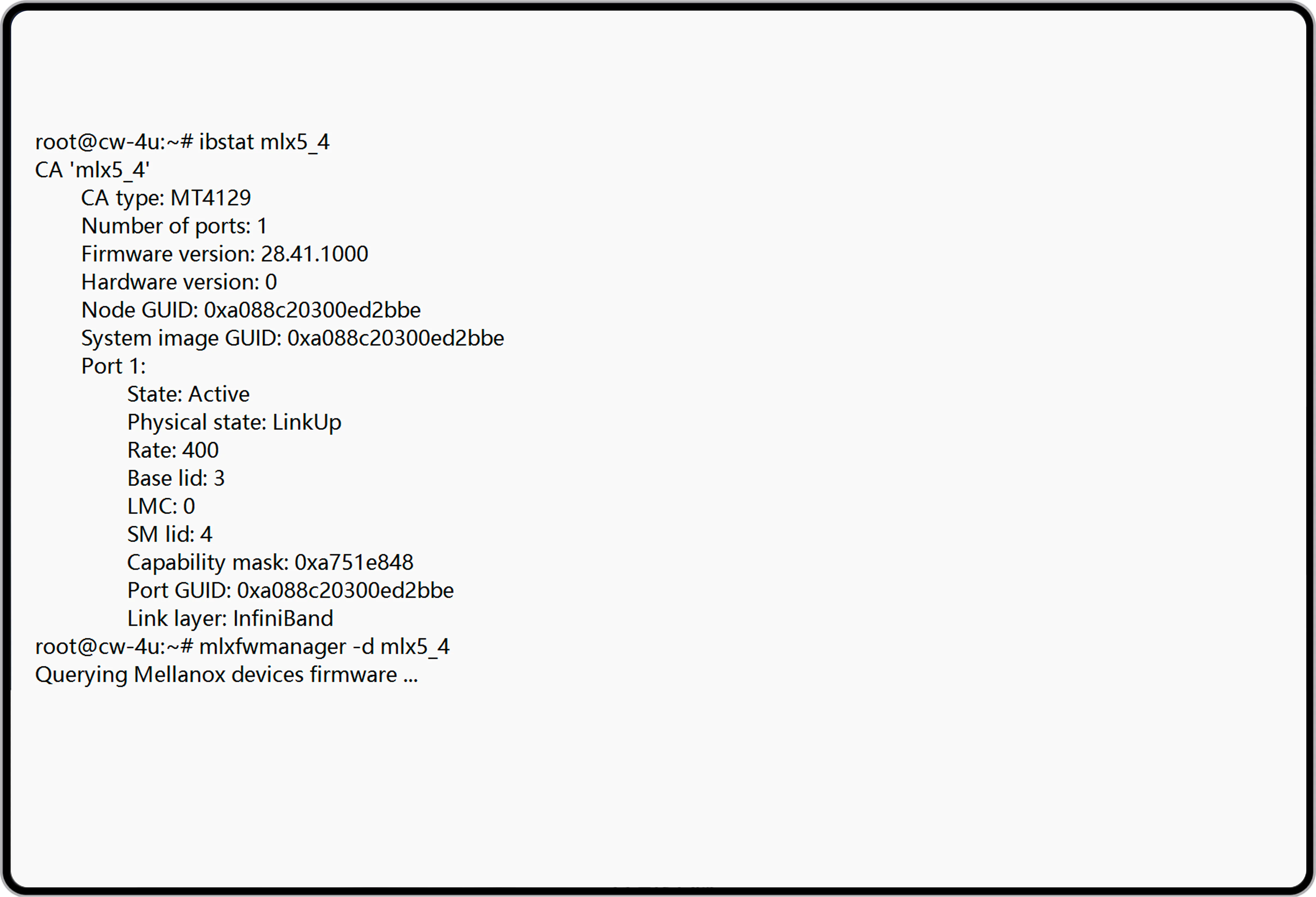
NADDOD OSFP-800G-2xDR4H Optisches Transceiver-Modul ist ein InfiniBand- und Ethernet-800Gb/s 2x400Gb/s Twin-Port OSFP, 2xDR4/DR8 Singlemode, paralleles 8-Kanal-Transceiver mit zwei 4-Kanal-MPO-12/APC optischen Steckern bei jeweils 400Gb/s. Das parallele Singlemode-Design mit Data-Center-Reichweite (8-Kanal, 2xDR4/DR8) verwendet 100G-PAM4-Modulation und erreicht maximal 100 Meter mit 8 Singlemode-Fasern. Der Twin-Port-2xDR4/DR8-Transceiver ist eine Schlüsselinnovation mit zwei internen Transceiver-Engines, die 64 Ports mit 400Gb/s in einem 32-OSFP-Gehäuse ermöglichen. Der OSFP-800G-2xDR4H wird in Quantum-2- und Spectrum-4-luftgekühlten Switches sowie ConnectX-7- und BlueField-3-DPUs eingesetzt.


NADDOD 800G OSFP 2×DR4/DR8 bietet überlegene Prozessreife, Hardwarezuverlässigkeit und Multi-Ökosystem-Kompatibilität. Fortschrittliche DSP-Equalization kompensiert optische Link-Störungen, gewährleistet stabile mittlere Übertragung und reduziert Betriebskomplexität. Im RS-FEC(272,257+1)-Test erreicht NADDOD 800G OSFP DR8 einen Pre-FEC-BER von -8~-11 und nahezu null Post-FEC-BER, ideal für Echtzeit-KI-Training und großskalige Cluster-Computing.

800G OSFP DR8 bietet eine kostengünstige, anwendungsspezifische Konnektivitätslösung für Rechenzentren. Die Nutzung kostengünstiger DACs für effiziente kurze Intra-Rack-Verbindungen reduziert den Bedarf an Zwischengeräten und Kosten. Für Inter-Rack-Übertragungen gewährleistet ein Modul- und Patchkabelansatz stabile Hochgeschwindigkeitsdatenübertragung. Die flexible Bereitstellungslösung balanciert Leistung und Kosten über verschiedene Übertragungsdistanzen und senkt effektiv die Gesamtbetriebskosten (TCO) sowie die Bereitstellungskomplexität. Es bietet eine leistungsstarke, kosteneffiziente Interconnect-Lösung für Architekturen aller Größenordnungen und beschleunigt die effiziente Bereitstellung und Optimierung von KI-Clustern.






,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX ISO140012015")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX ISO 90012015")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX ISO450012018")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX FDA")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX FCC")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX CE")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX RoHS")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX TUV-Mark")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX UL")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX WEEE")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX")
,MMS4X00-NS,980-9I30H-00NM00,InfiniBand 800G NDR Transceiver,OSFP 800G 2xDR4/DR8 Optik,Singlemode-Transceiver,100m,gekühlte Oberseite,LinkX")











5.0
5.0
5.0
5.0
5.0