










































 совместимый 1.6T OSFP224 DR8 IHS/Closed Finned Top InfiniBand XDR Silicon Photonics SMF Optical Transceiver для Quantum-X800 Air-Cooled Switches")
 совместимый 1.6T OSFP224 DR8 IHS/Closed Finned Top InfiniBand XDR Silicon Photonics SMF Optical Transceiver для Quantum-X800 Air-Cooled Switches")
 совместимый 1.6T OSFP224 DR8 IHS/Closed Finned Top InfiniBand XDR Silicon Photonics SMF Optical Transceiver для Quantum-X800 Air-Cooled Switches")
 совместимый 1.6T OSFP224 DR8 IHS/Closed Finned Top InfiniBand XDR Silicon Photonics SMF Optical Transceiver для Quantum-X800 Air-Cooled Switches")
 совместимый 1.6T OSFP224 DR8 IHS/Closed Finned Top InfiniBand XDR Silicon Photonics SMF Optical Transceiver для Quantum-X800 Air-Cooled Switches")
 Broadcom Sian3 | BCM83628
Broadcom Sian3 | BCM83628







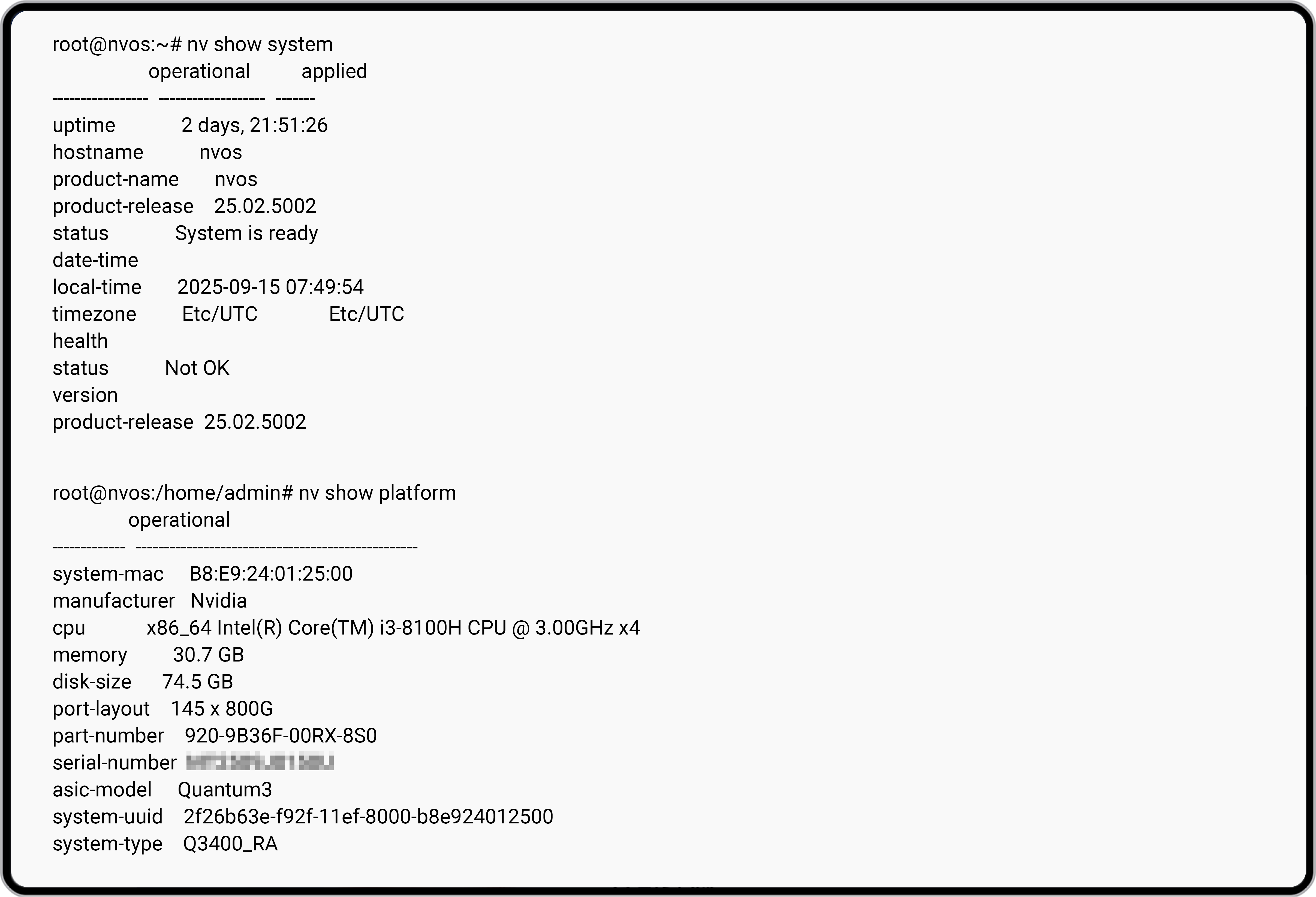
Проверенные в нескольких версиях программного обеспечения коммутатора Quantum-X800 Q3400-RA, трансиверы NADDOD 1.6T работают бесперебойно, гарантируя plug-and-play в реальных кластерах XDR.
Трансиверы NADDOD 800G бесперебойно работают в нескольких версиях программного обеспечения мезонинной сетевой карты ConnectX-8 на сервере HGX B300, обеспечивая plug-and-play в реальных кластерах XDR.








,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы ISO140012015")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы ISO 90012015")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы ISO450012018")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы FDA")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы FCC")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы CE")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы RoHS")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы TUV-Mark")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы UL")
,MMS4A00-XM,980-9IAH1-00XM00,1.6T OSFP224,1600G OSFP224, 1600G OSFP DR8,OSFP224 1.6T, Infiniband XDR, 1.6T OSFP224 DR8,1.6T OSFP,1.6T DR8,1.6T Silicon Photonics Optical Transceiver,Broadcom DSP,3nm DSP,Sian3,BCM83628,Quantum-X800 воздушно-охлаждаемые коммутаторы, Quantum-3 коммутаторы WEEE")




5.0
5.0
5.0
5.0
5.0